Description
This is a simple Flask-based web app that demonstrates using Fabric.js to implement a direct-manipulation SVG annotation tool. It has a bare-bones UI and layout (i.e., no Bootstrap or equivalent) and no production-level features such as authentication, authorization, document owners and assignments, error handling, concurrent access, deployment, etc. However, it does support most of the front end features desired, plus the connection to the back end. The original prototype supported adding new svg files by dropping them into the repository directory, which a DAO would pick up, creating corresponding json files as needed. This demo uses a fixed repository of a few files to keep it simple. The point is mainly to show the front end proof-of-concept using Fabric.js.
Motivation
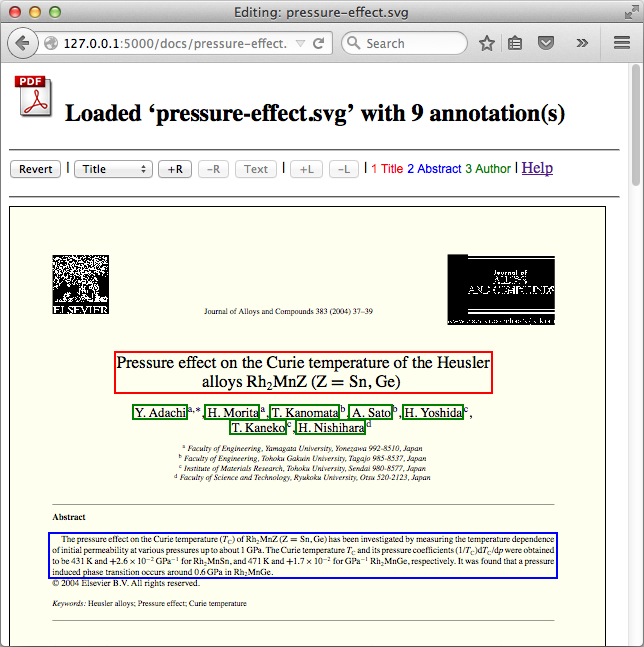
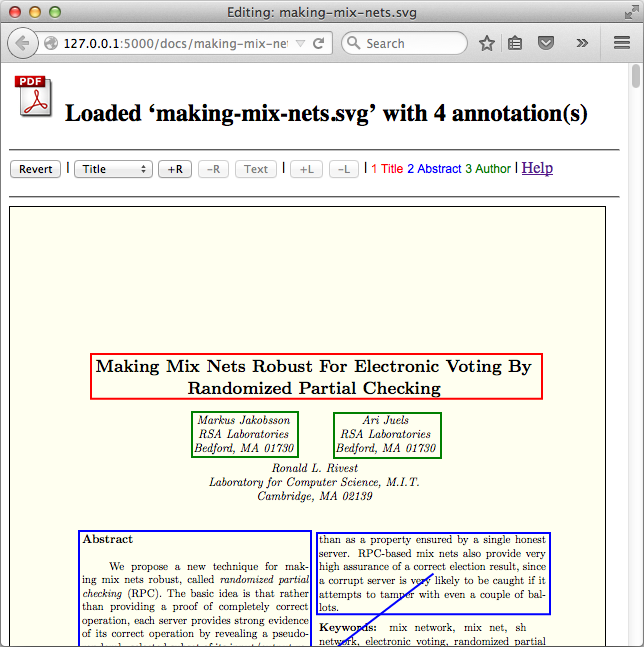 The fuller version of this tool was used to help a group of people annotate thousands of PDF files in SVG format as generated by Mozilla Labs' pdf.js. The SVG retains formatting and so is browser-renderable, but the markup is more useful for information extraction than that of PDF. The ultimate goal of the project was to create a gold standard for comparing the IE output to. Along with saving a document's annotations, users could ask the server for the text bounded by a particular annotation rectangle - a non-trivial problem with these complex SVG files (the 's generated are quite chopped up).
The fuller version of this tool was used to help a group of people annotate thousands of PDF files in SVG format as generated by Mozilla Labs' pdf.js. The SVG retains formatting and so is browser-renderable, but the markup is more useful for information extraction than that of PDF. The ultimate goal of the project was to create a gold standard for comparing the IE output to. Along with saving a document's annotations, users could ask the server for the text bounded by a particular annotation rectangle - a non-trivial problem with these complex SVG files (the 's generated are quite chopped up).
The decision to to write a tool was made after I researched existing annotation tools including some amazing ones:
Unfortunately they lacked the customization and power user features we needed for the high-throughput workflow necessary to annotate 1000s of SVG files. I then surveyed JavaScript graphics libraries (both Canvas- and SVG-based) to find one to support the rectangle-based UI we wanted. I settled on the excellent Fabric.js (the demos are awesome) after having looked at general purpose ones (of which there are many) including:
I also looked at diagram-oriented libraries, but they felt like too much work compared to a straightforward canvas wrapper.
In the end I liked Fabric best for its inbuilt support of handles and grouping, and its solid level of activity. And it worked pretty well, modulo a number of gotchas. It's a really nice piece of work, as are many of these. The JavaScript graphics library scene is definitely alive and well.
Code tour
 While I don't have my client's permission to share the code, I'll sketch out the implementation for the curious.
While I don't have my client's permission to share the code, I'll sketch out the implementation for the curious.
Routes
At the top level of this standard Flask MVC app is app/routes.py, which has four URIs/controllers:
/: app/templates/index.html template. Lists the SVG files in the fake DAO./docs/<fileName>: app/templates/edit.html template. Described below./docs/<fileName>/annotations: REST API endpoint for getting a document's annotations as a JSON array. Finds and reads the JSON file corresponding to the SVG file and returns it as 'application/json'./docs/<fileName>/text: placeholder endpoint for calculating the text bounded by a rectangle. Pulls the rectangle bounds from the query parameters and returns a fake string.
edit.html
This view has a simple vanilla HTML editing section at the top with three hard-coded annotation types, and the editing area underneath. The latter layers the Fabric canvas on top of the SVG file, whose element is inserted dynamically via loadSvg() in app/static/edit-document.js (see below). Finally, edit.html sets the variables needed by edit-document.js, based on the Flask-injected fileName variable, and loads the Fabric and edit-document.js.
edit-document.js
This file does the heavy lifting. On load it links up the button and shortcut actions to their methods and then calls loadSvg() to load the SVG document and its annotations. It does so using an AJAX call because of a browser SVG loading bug where the SVG size is reported incorrectly until it's completely loaded. Once it's loaded, loadSvg() inserts the SVG element behind the Fabric canvas, sets its size, and then initializes the Fabric canvas, saving it as an application property on the canvas element for easy access. Once that's all done, the function calls loadAnnotations(), which performs the AJAX call to /docs/<fileName>/annotations and then creates Fabric Rect objects for each, using the correct color for the annotation type.
One tricky bit was handling the line connecting linked Rects. Lines are managed explicitly (there is no built in 'connector' feature in Fabric), so their endpoints must be dynamically adjust during rectangle moves and resizes, and pointers to/from them must be saved as properties on the Fabric objects (i.e., a Rect needs to know all of its Lines, and a Line needs to know its two endpoints' Rects).
The rest of the code manages all the fiddly aspects of the app - resizing, duplicating, linking, etc. And of course button state must be updated based on selection changes. The only other mildly interesting thing is the AJAX call to get an annotation rect's text - a straightforward call to the /docs/<fileName>/text endpoint.
User Documentation
The UI is a straightforward direct manipulation one where users work with rectangle objects. Click to select, drag to move, drag resize handles to resize, click the delete rectangle button to remove, etc. The only feature that's non- obvious is how to add and remove links between rectangles. To add a link, select exactly two rectangles with the same label and no existing link and then click the add link button. To remove a link, select two rectangles with an existing link and the click the remove link button. Keystroke shortcuts are supported for power users:
Keystroke shortcuts
Types
1: set current type to Title
shift + 1: filter all but Title
2: set current type to Abstract
shift + 2: filter all but Abstract
3: set current type to Author
shift + 3: filter all but Author
Escape: reset filter
Create
+: create new annotation using current type
Move & Resize
arrow key: move selection 1px
shift + arrow key: move selection 10px
option + arrow key: resize selection 1px
shift + option + arrow key: resize selection 10px
Delete/Duplicate
backspace|delete: delete selection
control + d: duplicate selection
Select
tab: select next
shift + tab: select previous
Text Feedback
x: display text for selection


 Since leaving my research programmer position at UMass (funding was drying up), I've been reaching out to leaders to explore possible contributions I could make in the progressive or educational spaces 1. Here I'd like to briefly share a few notes from my conversation with one of them, Josh Silver. NB: Any errors I make are my own - please send corrections!)
Since leaving my research programmer position at UMass (funding was drying up), I've been reaching out to leaders to explore possible contributions I could make in the progressive or educational spaces 1. Here I'd like to briefly share a few notes from my conversation with one of them, Josh Silver. NB: Any errors I make are my own - please send corrections!) Matthew Cornell
Matthew Cornell




{kind=link}
{kind=link}
{kind=link}